

LLM Assisted Vulnerability Scanner: Our BTech Project Journey: Lessons, Challenges, and Triumphs


Introduction
In the modern era, software systems are indispensable to industries ranging from finance to healthcare. As these systems grow in complexity, security vulnerabilities have become increasingly prevalent, leading to significant financial and reputational damages. Studies indicate that small businesses face an average loss of $227,014 per security incident, while the global cost of data breaches averages $4.45 million.
Static code analysis tools are essential for detecting vulnerabilities early in the development process, helping to minimize the expenses associated with resolving issues at later stages. However, these tools face significant limitations, including high false positive rates, lack of contextual understanding, and incomplete or inaccurate taint specifications. These challenges result in inefficient manual review processes and overlooked vulnerabilities.
To overcome these limitations, we introduce a novel solution, Sanj AI, which combines Large Language Models (LLMs) with static analysis tools to improve the detection of security vulnerabilities, with a particular focus on Java-based repositories. Our solution leverages LLMs for automated inference of taint specifications and contextual reasoning, thereby reducing reliance on manually labeled data and improving detection accuracy. By combining the generative capabilities of LLMs with the systematic analysis of static tools, this approach minimizes false positives and identifies previously undetected vulnerabilities. This neuro-symbolic methodology provides a scalable and effective framework for comprehensive repository analysis in real-world projects, advancing the field of security vulnerability detection within the domain of Generative AI and Security.
Ideation and Problem Formulation
Software security has become a critical concern as the complexity of applications and the prevalence of cyber threats continue to increase. To address vulnerabilities early in the development process, static code analysis tools are employed to identify and mitigate risks within the source code. These tools enable developers to detect issues such as security flaws, code smells, and performance bottlenecks without executing the code.
In this project, we propose a system that integrates static code analysis with advanced capabilities of Large Language Models (LLMs) to improve the precision and scope of vulnerability detection. The system leverages CodeQL, a robust static analysis tool, alongside the Groq API, which facilitates the use of LLMs. The focus of the proposed system is limited to Java repositories, given their widespread use in enterprise applications and their susceptibility to various security vulnerabilities.
Additionally, to test the efficacy and accuracy of this tool, we selected the Verademo repository. This repository is well-documented and includes exploitable vulnerabilities with Common Weakness Enumeration (CWE) identifiers, making it an ideal candidate for evaluating our proof of concept. By combining CodeQL’s querying capabilities with the contextual understanding offered by LLMs, this tool aims to bridge gaps in traditional static analysis, providing actionable insights into code security.
Key Problem Areas that we will focus on:
- False Positives: High rates that consumed time and resources.
- Irrelevant Reports: Misaligned with the actual code context.
- Incomplete Taint Specifications: Hindering accurate detection of data flow vulnerabilities.
Planning and Execution
Phase 1: Research and Setup
The initial phase involved laying the foundation. We conducted an in-depth literature review, analyzing tools and techniques that could support our vision. From CodeQL for static analysis to NVIDIA’s NIM API for LLM integration, we meticulously curated our tech stack.
- Challenges: Limited documentation for CodeQL and high learning curves for LLM integration.
- Solution: Extensive use of forums, tutorials, and direct communication with authors of relevant research papers.
Phase 2: CodeQL Source and Sink Queries
We began by developing queries to identify vulnerabilities within source code. These queries formed the backbone of our static analysis system, targeting critical CWE (Common Weakness Enumeration) categories.
- Challenges: Lack of predefined queries for nuanced vulnerabilities.
- Solution: Iterative refinement and custom query development tailored to our objectives.
Phase 3: LLM Integration
Integrating LLMs into our system was both exciting and challenging. The advanced contextual understanding offered by LLMs elevated our analysis but came with its own hurdles.
- Challenges: Unpredictable outputs and API rate limiting.
- Solution: Experimentation with multiple models to find optimal configurations and validation methods.
Phase 4: UI Development and Results Presentation
To make our tool accessible, we developed a user-friendly interface that showcased results in an organized and actionable manner. This phase also involved a detailed comparative study of various detection methods.
- Challenges: Ensuring compatibility and real-time responsiveness.
- Solution: Modular design and extensive testing to iron out inefficiencies.
High-Level Design of Sanj-Ai System
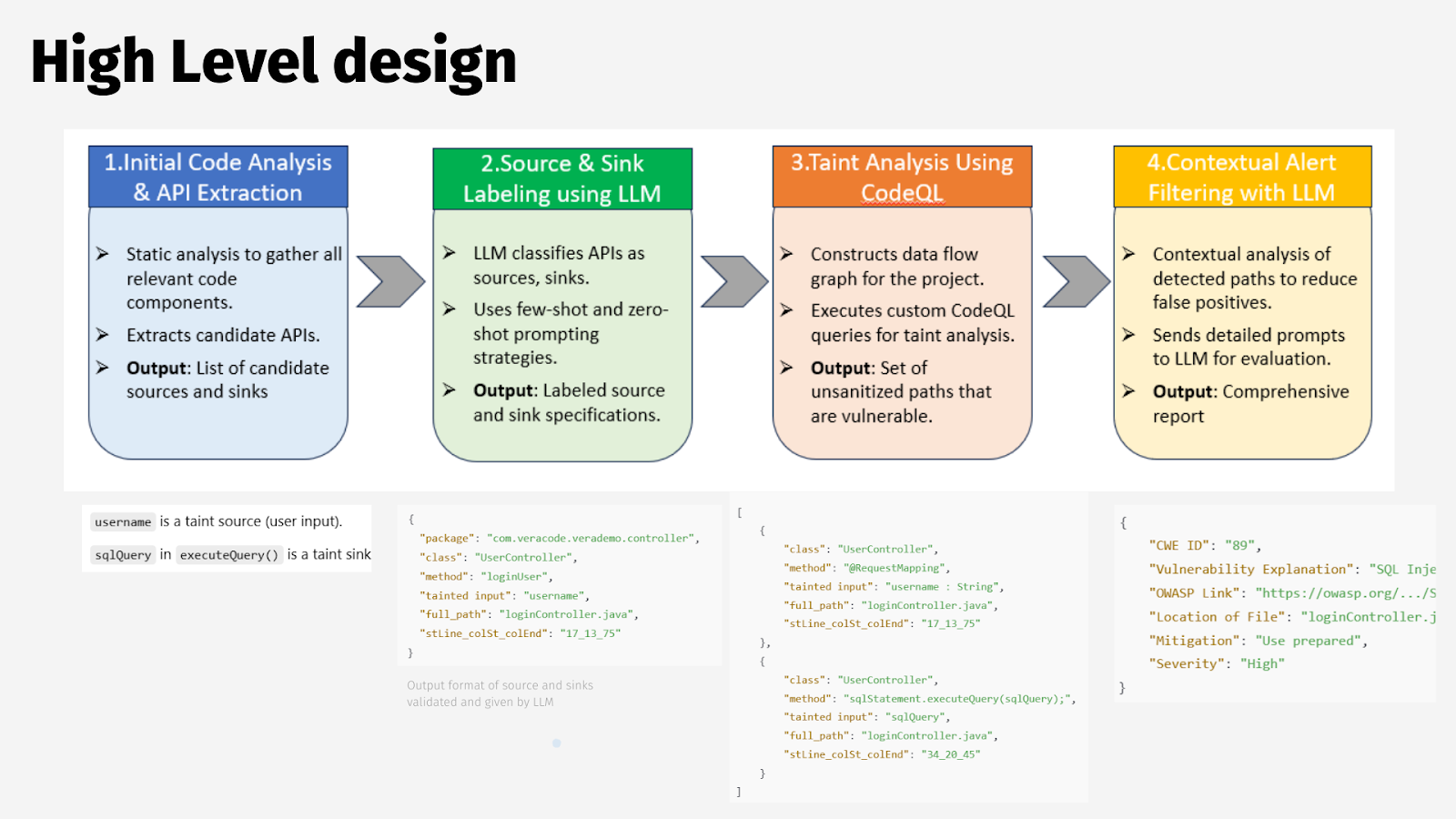
Figure: System Architecture Diagram
The high-level design elaborates on how the workflow is implemented with a focus on static analysis, LLM integration, and taint analysis:
Initial Code Analysis and API Extraction:
Uses static code analysis tools to extract relevant components.
Identifies potential APIs that could serve as taint sources or sinks.
Output: A list of candidate sources and sinks.
Source and Sink Labeling Using LLM:
LLM classifies APIs as sources or sinks based on predefined criteria.
Employs few-shot and zero-shot learning strategies for efficient classification.
Output: A labeled list of source and sink specifications.
Taint Analysis Using CodeQL:
Constructs a data flow graph to visualize taint propagation.
Executes custom CodeQL queries to identify paths between sources and sinks.
Output: A list of unsanitized paths that are vulnerable.
Contextual Alert Filtering with LLM:
Analyzes detected paths for context using LLM to reduce false positives.
Provides detailed explanations and recommendations for mitigation.
Output: A comprehensive vulnerability report.
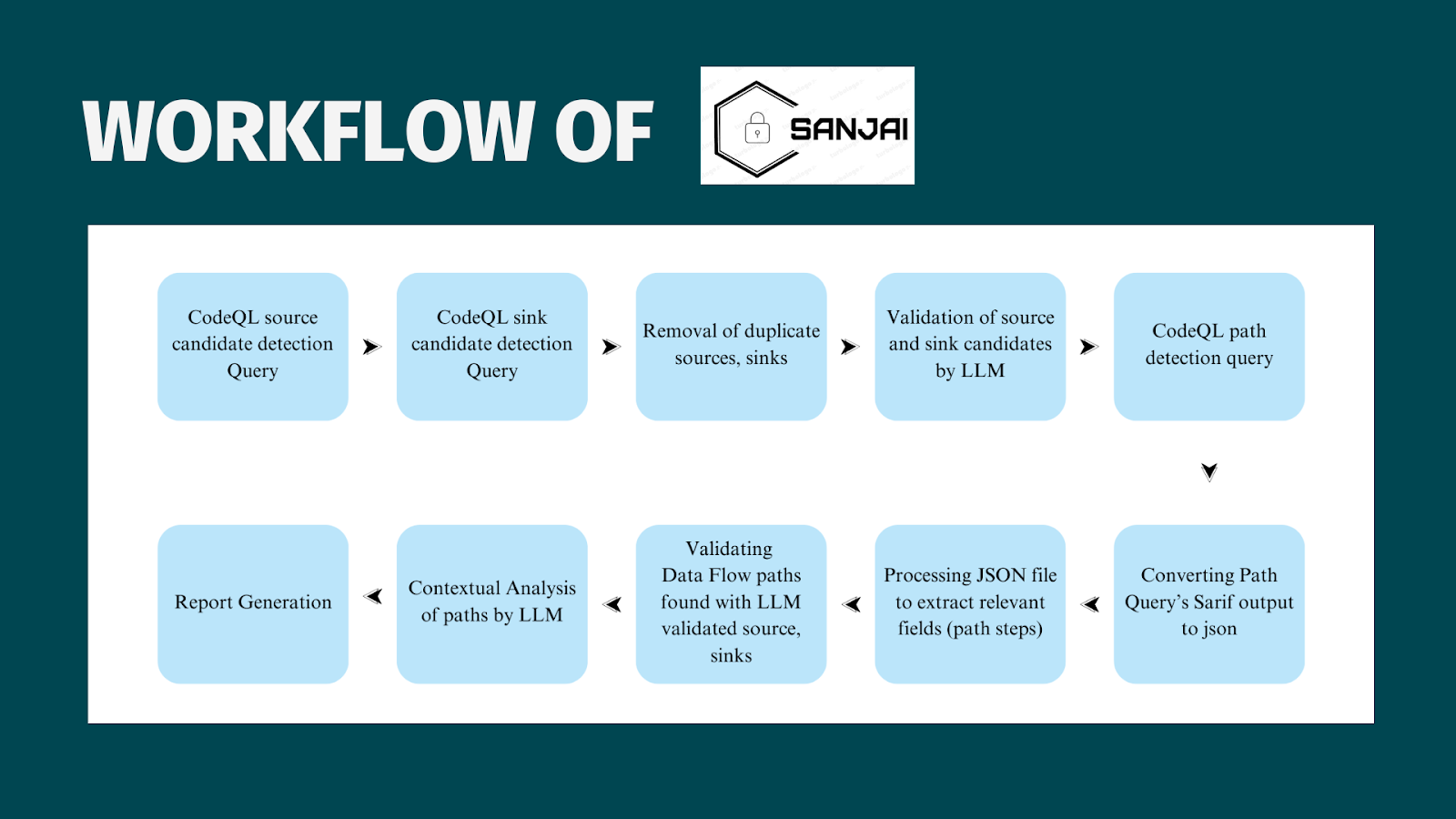
Figure: Data Flow Diagram
Key Discoveries
CodeQL Scanning Results on Verademo:
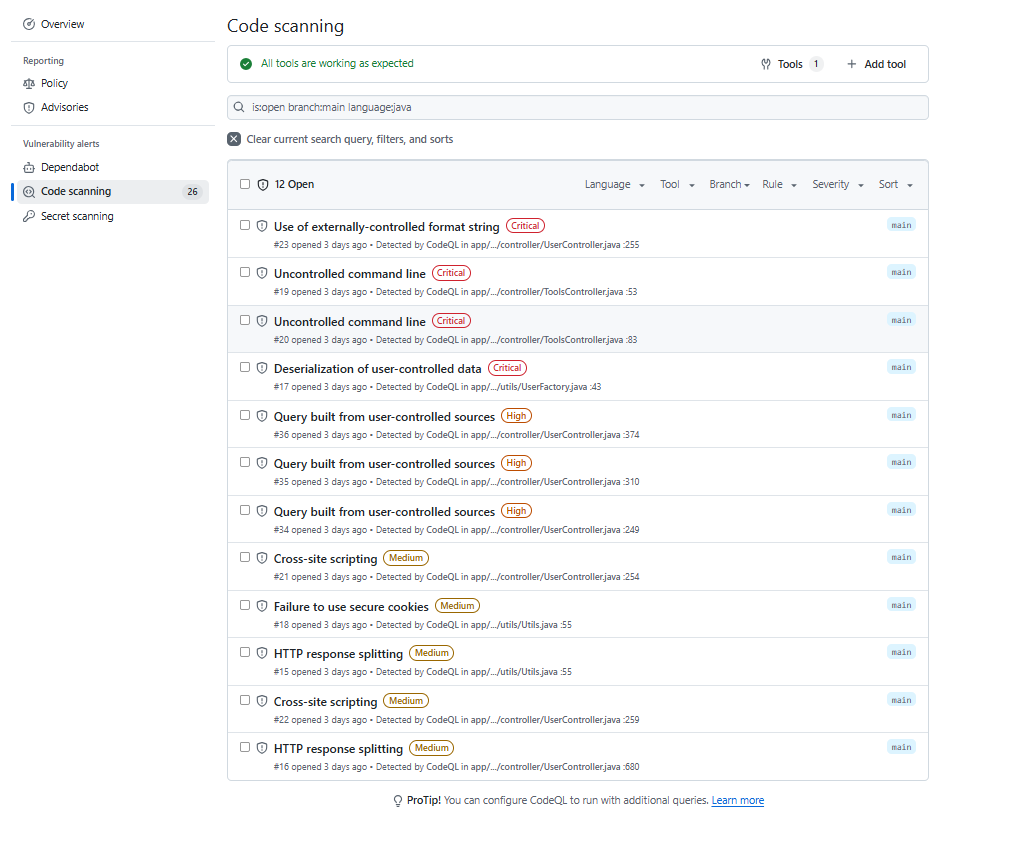
Figure: CodeQL Report Image
These are the results of a verademo repository scan done by CodeQL .
CodeQL detected 26 vulnerabilities in the repository, out of which 12 were pertaining to Java.
Sanj-AI results and comparison:
CWE ID | Actual Java Vulnerabilities | Detected by CodeQL | Sanj-AI using mistralai/mixtral-8x7b-instruct-v0.1Using Nvidia Nim | Sanj-AI using nvidia/llama-3.1-nemotron-70b-instructUsing Nvidia Nim | Sanj-AI using meta/llama-3.1-70b-instructUsing Nvidia Nim | Sanj-AI using Llama-3.1-70b-versatileUsing Groq Api | Sanj-AI using Llama-3.2-90b-vision-preview using Groq Api | Max detected by Sanj-AI | CodeQL’s Accuracy per CWE ID | Sanj-AI’s Accuracy per CWE ID |
73 | 2 | 0 | 2 | 1 | 2 | 2 | 2 | 2 | 0% | 100% |
78 | 2 | 2 | 1 | 1 | 2 | 2 | 1 | 2 | 100% | 100% |
80 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 50% | 50% |
89 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 100% | 100% |
113 | 2 | 2 | 1 | 1 | 1 | 1 | 0 | 1 | 100% | 50% |
117 | 2 | 0 | 2 | 2 | 1 | 2 | 2 | 2 | 100% | 100% |
200 | 3 | 1 | 2 | 0 | 0 | 0 | 0 | 2 | 33% | 67% |
134 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 50% | 0% |
327 | 4 | 0 | 1 | 3 | 2 | 2 | 2 | 3 | 0% | 75% |
470 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0% | 100% |
501 | 2 | 0 | 2 | 2 | 2 | 2 | 2 | 0 | 0% | 0% |
502 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 100% | 0% |
601 | 3 | 0 | 2 | 2 | 2 | 1 | 1 | 2 | 0% | 67% |
Total | 30 | 12 (40 %) | 18 (60%) | 17 (56%) | 17 (56%) | 16 (53%) | 15 (50%) |
Table: Comparative Study of CodeQL and Sanj-AI Results
The results show that Sanj-AI models outperform CodeQL in detecting vulnerabilities across various CWE IDs. While CodeQL detected vulnerabilities in 40% of cases, Sanj-AI achieved higher detection rates with its different models. The mistral/mistral-8x7b model had the best performance, detecting 60% of vulnerabilities, followed by nvidia/llama-3.1-nemotron-70b and meta/llama-3.1-70b, both identifying 56% of vulnerabilities. The llama-3.1-70b-versatile and llama-3.2-90b-vision-preview models had detection rates of 53% and 50%, respectively. These results highlight the superior accuracy of Sanj-AI compared to CodeQL, demonstrating the potential of AI-driven models in vulnerability detection.
With respect to accuracy of LLMs, LLMs occasionally validated incorrect taint sources and sinks leading to false positives.
This was due to insufficient contextual information caused by token limits and API rate limiting.
Limited input restricted the LLM's ability to gain a complete understanding of the code, impacting accuracy.
This project serves as a strong proof of concept, showcasing how LLMs can augment traditional tools, to increase accuracy. With the increasing accuracy and accessibility of high-performing LLMs in the near future, such integrations are poised to become both highly effective and essential for advanced code analysis.
1.Enhanced Detection Accuracy
By combining CodeQL’s systematic analysis with LLMs’ contextual reasoning, we achieved a significant improvement in accuracy. For instance, Sanj-AI, our developed tool, outperformed traditional static analysis tools by detecting up to 60% of vulnerabilities in cases where others capped at 40%.
2.Reduction in False Positives
LLMs played a pivotal role in disambiguating flagged vulnerabilities, reducing irrelevant noise and enabling developers to focus on actionable issues.
3.Contextual Insights
A standout aspect was the ability of LLMs to understand the intent behind code. This allowed our tool to identify vulnerabilities that static analysis alone would overlook.
User Interface
Figure: Home page

Figure: Report on web Image
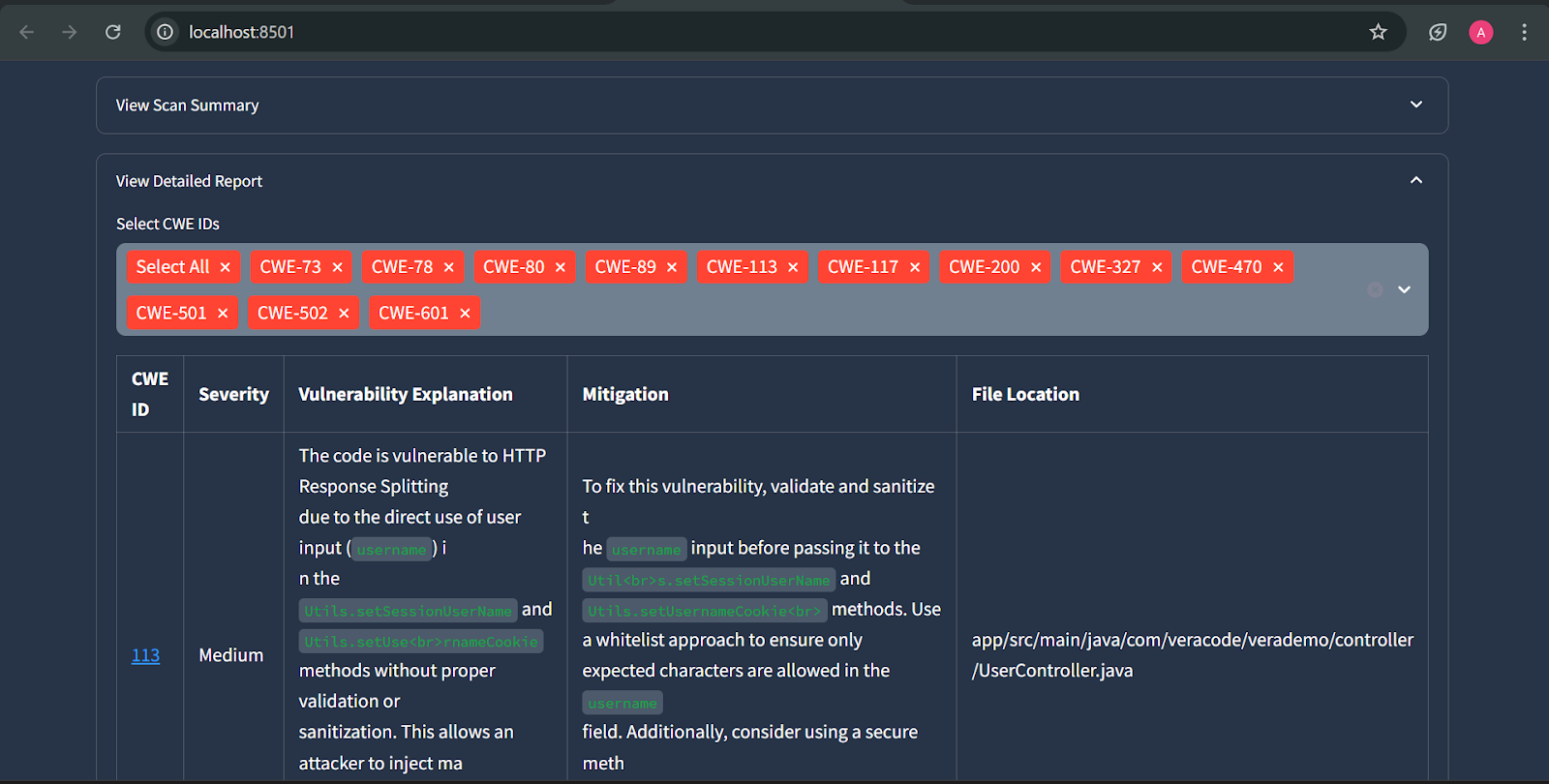
Figure: Report summary
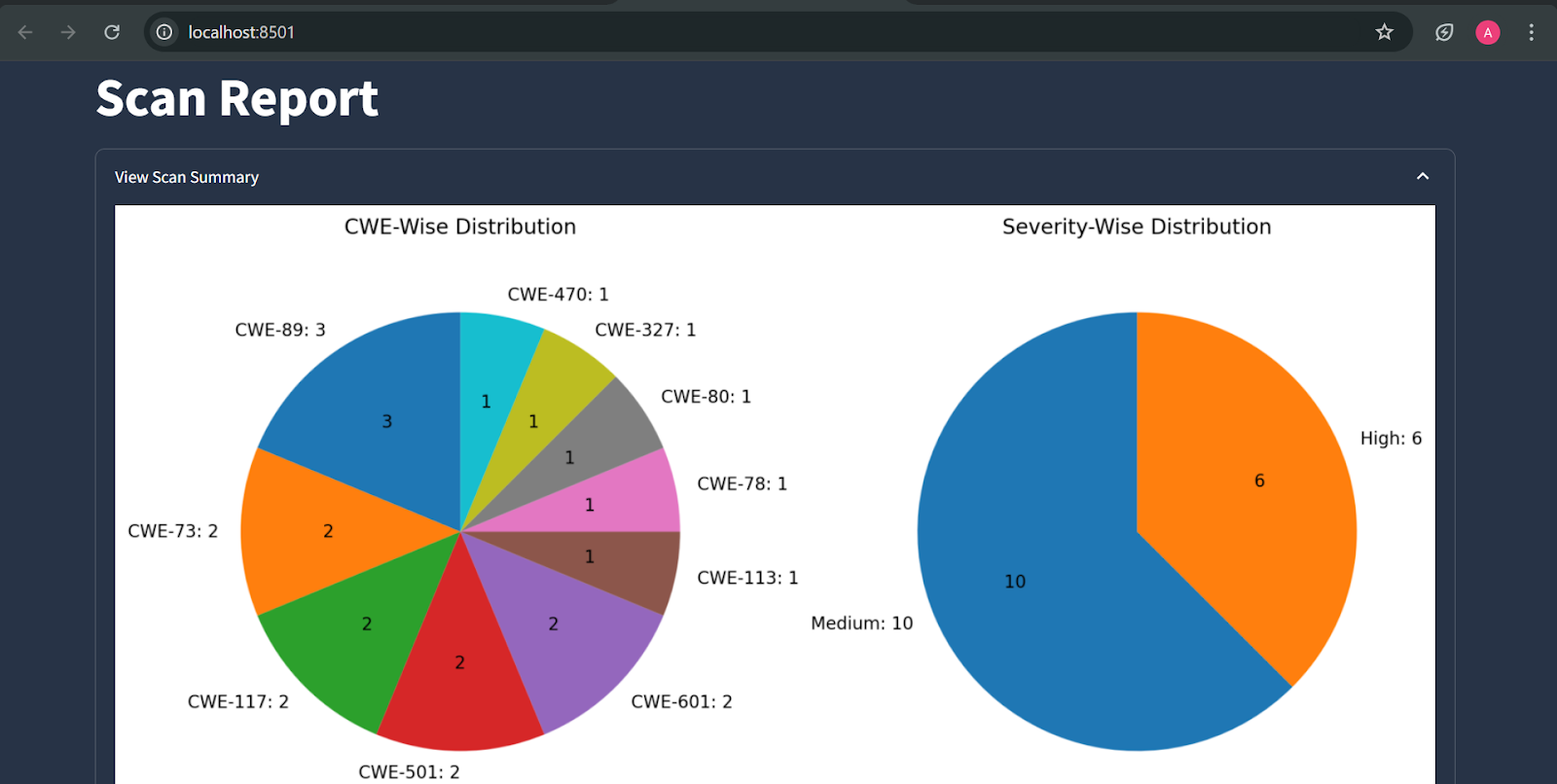
Figure: Detailed report
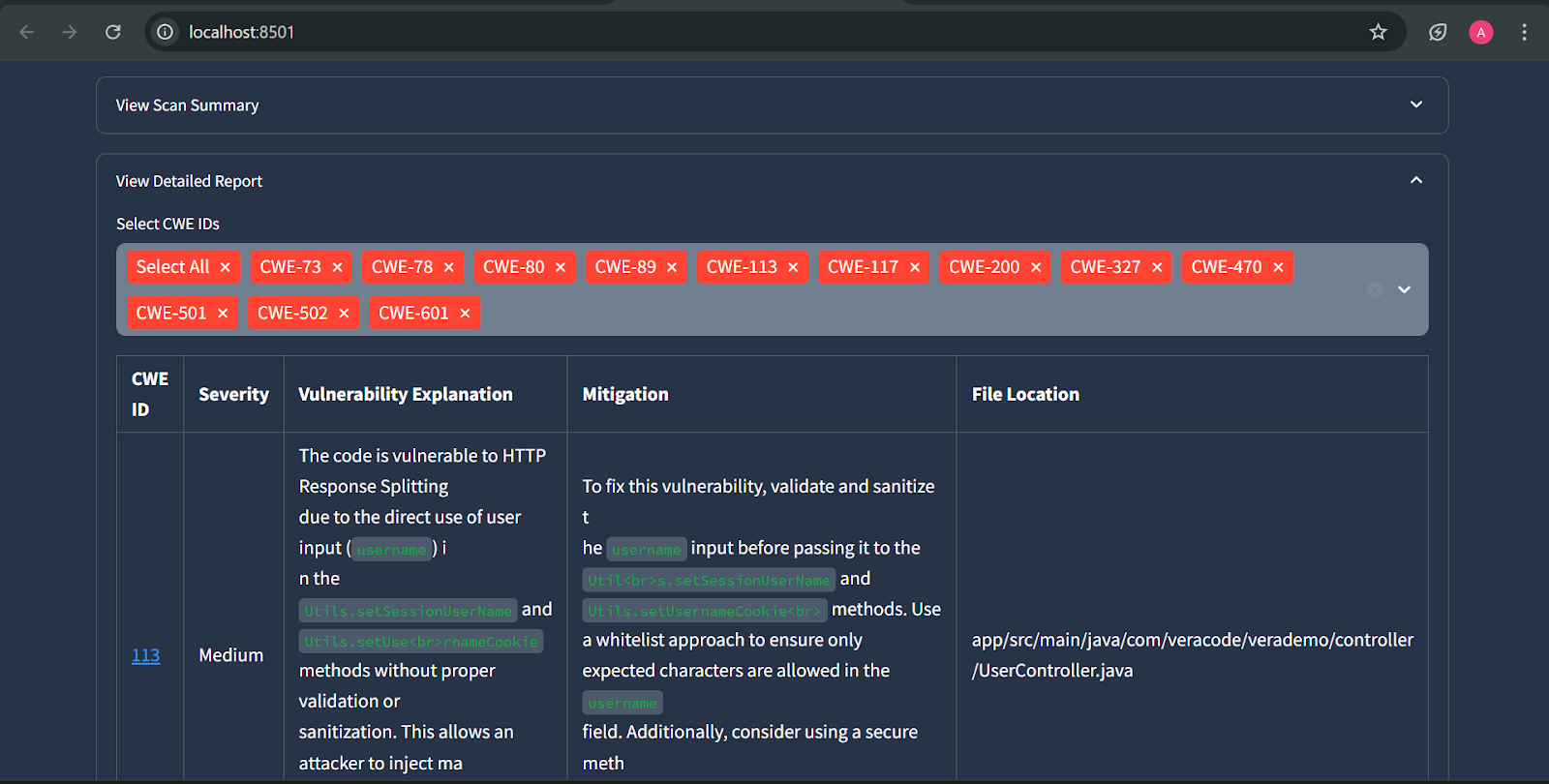
Figure: Detailed report summary (downloaded PDF)
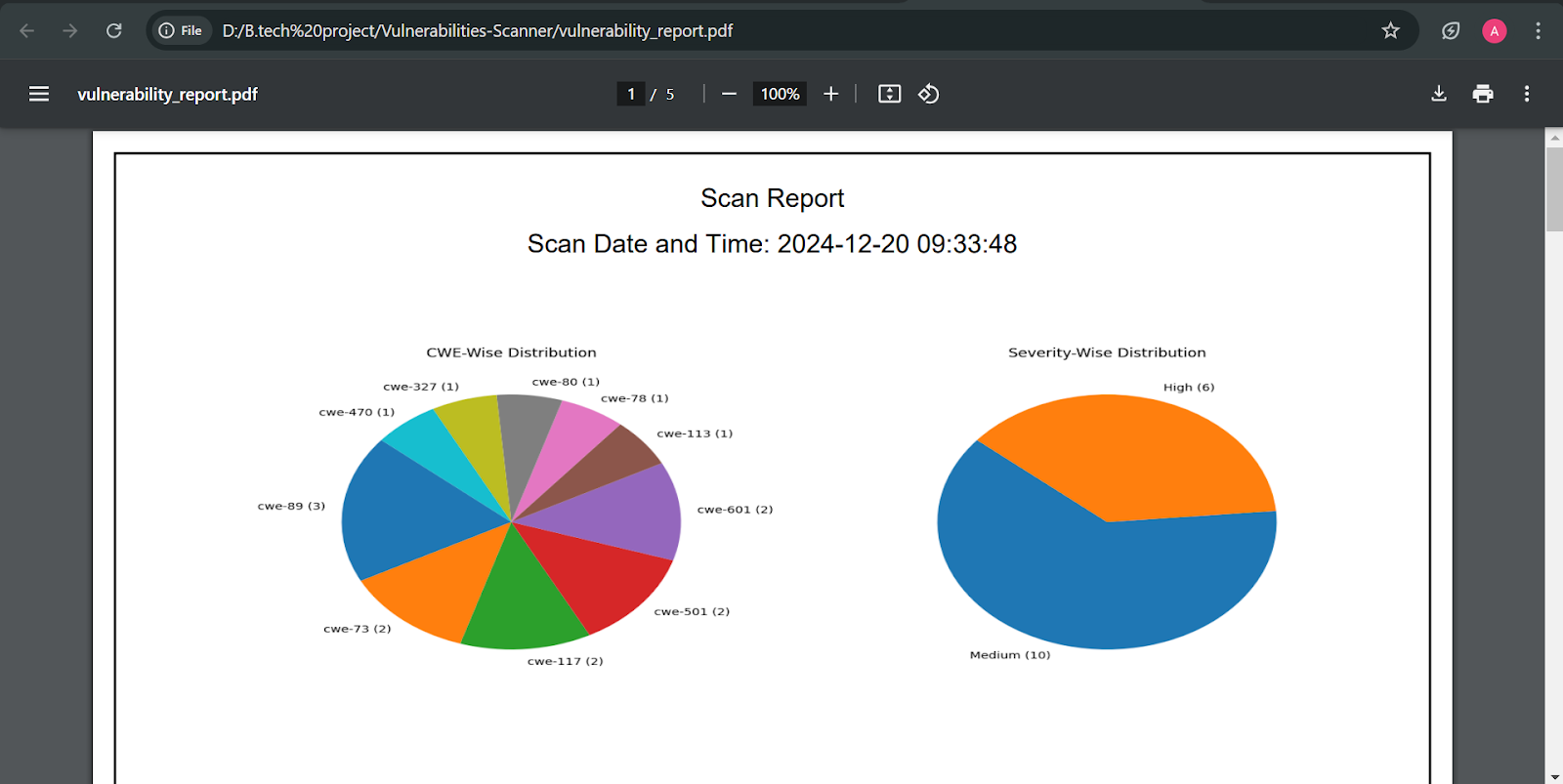
Figure: Detailed downloadable report
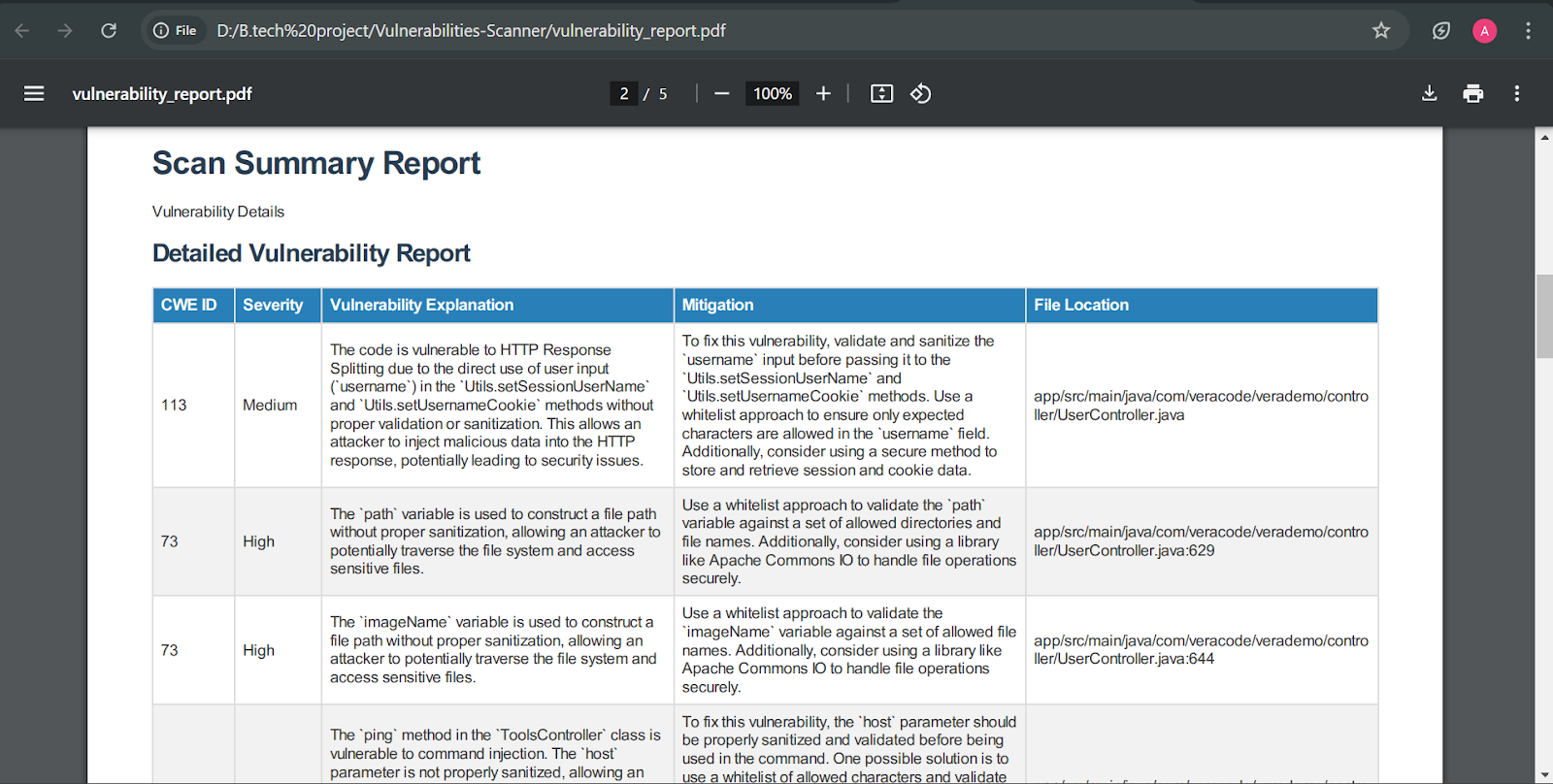
Challenges We Overcame
CodeQL Limitations: With limited resources and documentation, navigating CodeQL’s capabilities was initially daunting. Our strategy involved collaborative learning and reaching out to experts.
LLM Token Constraints: Token limits restricted comprehensive understanding during validation. We optimized prompts and utilized API resources effectively.
Integration Bottlenecks: Merging static and dynamic analysis approaches required extensive debugging and testing.
Comprehensive Aspects Covered
System Design Details
Our project involved creating a layered architecture:
Taint Tracking and LLM Integration: Combining traditional taint tracking with LLMs to monitor and refine data flow analysis.
Results and Reporting Layer: Generating structured, actionable vulnerability reports in formats like HTML and JSON.
Source Code Repository: Using a centralized repository for analysis and intermediate representation of the code.
CodeQL Queries and Database: Designing tailored queries to track unsafe data and building a relational database for comprehensive analysis.
System Implementation
The workflow began with environment initialization, followed by:
- Validating prerequisites like the CodeQL database.
- Running static analysis queries and storing results in CSV/SARIF formats.
- Using Python scripts for deduplication and LLMs for advanced validation.
- Generating final reports through contextual analysis and visualization tools.
Test Results
Testing on the Verademo repository revealed:
- CodeQL detected 26 vulnerabilities, while Sanj-AI models identified 15-28 vulnerabilities across different CWE categories, demonstrating superior accuracy.
- Comparative studies showed Sanj-AI reduced false positives and highlighted critical vulnerabilities missed by traditional tools.
Observations from Repository Analysis
We analyzed repositories like Apache NiFi, Apache Spark, and the Verademo repository, identifying issues such as insecure configurations and SQL injection flaws. The Verademo repository, chosen for its rich vulnerability dataset, served as the primary testbed for our tool.
Recommendations for Future Teams
To aspiring developers, we share these lessons:
Thorough Planning: Define clear objectives and prepare for contingencies.
Resourcefulness: Make the most of available resources, including forums, research papers, and community support.
Team Collaboration: Harness the diverse strengths of your team to overcome roadblocks.
Iterative Refinement: Constantly revisit and improve your methods and tools.
Understanding Context: Focus on domain-specific issues to tailor solutions effectively.
Conclusion
Our BTech project journey was more than an academic exercise; it was a transformative experience. We not only built a solution to enhance security vulnerability detection but also grew as developers and collaborators. By integrating static analysis tools with LLMs, we demonstrated how innovation and persistence can overcome significant challenges.
This blog captures every aspect of our journey, serving as a guide for others. We hope our experiences inspire future teams to innovate fearlessly, learn continuously, and build solutions that make a difference. Here’s to innovation, perseverance, and the collective pursuit of excellence!